📢 当サイトをご覧のみなさまへ
いつもありがとうございます。当サイトでは 海外バイナリオプションであるBubingaと提携しています。まずは無料口座から気軽に体験できて、 当サイト経由では1万円を得られるチャンスもご用意しています🎵
気になった方は、記事の最後もぜひ読んでみてください🐾
なお、どのような場合であっても記事は中立性を心がけております。
テレグラムのmessageの処理において、太字など装飾がされていた時に読み取りできない問題に対処する方法を検討しているところです。
テレグラムAPIから受け取るメッセージのフォーマットを正確に処理するためには、メッセージ内の書式情報(エンティティ)を正確に解析し、必要に応じてMarkdown形式に変換していたのですが、今回の検証により、以前のコードが太字(bold)のエンティティを正しく処理できていなかったことが判明しました。
この記事では、この問題を修正するために最新のテレグラムAPIドキュメントを紹介し、コーディングついても言及したいと思います。
最新のテレグラムAPIドキュメントの特徴
テレグラムAPIは、メッセージの取得と解析において、さまざまなフォーマット情報を提供しています。最新のドキュメントによると、以下のような特徴があります:
- エンティティ情報の拡充: テレグラムAPIは、メッセージ内のテキストに対して詳細な情報を提供します。これには、
bold(太字)、italic(斜体)、underline(下線)、strikethrough(取り消し線)、code(コードブロック)など、複数の書式タイプが含まれています。これにより、メッセージのフォーマットを正確に再現することが可能です。 - エンティティのネストと重複の処理: 最新のAPIは、エンティティのネスト(入れ子構造)や重複をサポートしています。たとえば、太字と斜体が同じテキストに適用されている場合、それを正確に再現するための情報が提供されます。
- 統一されたメッセージフォーマット: テレグラムAPIは、メッセージに関する情報を統一された形式で提供し、エンティティのオフセットと長さ(length)に基づいてテキストを操作することができます。これにより、テキストの一部に対してさまざまなスタイルを適用することが容易になります。
- 高度なメッセージ操作のサポート: 最新のテレグラムAPIは、メッセージの編集、削除、返信といった操作もサポートしています。
最新バージョンのコード修正
以下に、最新のテレグラムAPIドキュメントを参照して修正したコードを示します。このコードは、エンティティ情報を正確に解析し、太字やその他の書式をMarkdown形式で適切に反映させることができるようになっています。
一部抜粋※
def extract_formatted_text(self, message):”””メッセージの書式情報を使用してテキストを抽出し、Markdownとしてフォーマットする”””
if ‘text’ in message:
text = message[‘text’]
if ‘entities’ in message:
entities = message[‘entities’]
formatted_text = “”
last_offset = 0
for entity in entities:
offset = entity[‘offset’]
length = entity[‘length’]# 書式なしのテキスト部分を追加
if last_offset < offset:
formatted_text += text[last_offset:offset]
# 書式付きのテキストを追加
entity_text = text[offset:offset + length]
if entity[‘type’] == ‘bold’:
formatted_text += f”**{entity_text}**” # 太字用のMarkdown記法
elif entity[‘type’] == ‘italic’:
formatted_text += f”_{entity_text}_” # 斜体用のMarkdown記法
elif entity[‘type’] == ‘underline’:
formatted_text += f”<u>{entity_text}</u>” # 下線用のHTML記法(Markdownには下線記法がないため)
elif entity[‘type’] == ‘strikethrough’:
formatted_text += f”~~{entity_text}~~” # 取り消し線用のMarkdown記法
elif entity[‘type’] == ‘code’:
formatted_text += f”`{entity_text}`” # コード用のMarkdown記法
else:
formatted_text += entity_text # 他の書式はそのまま
last_offset = offset + length
# メッセージの最後の部分を追加
formatted_text += text[last_offset:]
return formatted_text
else:
return text # エンティティがない場合はそのまま返す
return ”
def process_message(self, message):
try:
message = message.upper().replace(“\n”, ” “)
print(“Processed message:”, message)
signals = []
改善内容の要約
- エンティティ処理の強化: 太字や斜体だけでなく、下線、取り消し線、コードブロックなどの他の書式も適切に処理するように改善しました。
- フォーマット情報の正確な適用: 各エンティティのオフセットと長さを正確に計算し、テキストの全範囲に適用しました。
- 最新のテレグラムAPIへの対応: 最新のAPIドキュメントを参照し、変更点を反映させることで、より信頼性の高いメッセージ処理を実現しました。
結論
これらの改善により、テレグラムからのシグナル取得とフォーマット処理がより正確かつ効率的になりました。この新しいコードバージョンは、最新のテレグラムAPIに完全に対応しており、取引戦略の実行において重要なリアルタイムシグナルの処理をより信頼性の高いものにします。これにより、トレーダーは市場の動きをリアルタイムで捉え、迅速かつ正確な意思決定を行うことが可能となります。
💡 BubingaBOで 「そだし限定シグナルパック」と3つの検証支援特典を受け取る
2020年代後半、長期積立や分散投資が当たり前の選択肢となった退屈な時代。それでもなお、人間には「今夜の自分の判断が正しかったか」を即座に確かめたいという、疼くような根源的欲求があります。
当サイトでは、バイナリーオプションを人生を破滅させるギャンブルではなく、「損失の上限を事前に固定した上で、自らの相場観を少額・短期で測るための実験場(短期検証枠)」として静かに定義しています。
📋 本サイト経由でBubingaを登録する前に確認すること

※本サイトはBubingaとアフィリエイト提携をしています。以下の公式登録リンクからアカウントを作成した場合に限り、限定の検証支援特典が適用されます。なお、上記画像には含まれておりませんが、FXシグナルパック(19,800円相当)の永久提供もございます。
| 特典内容 | 詳細仕様・適用条件 |
|---|---|
| そだしFXシグナルパック (19,800円相当) | 永久無料付与(詳しくはこちら) |
| VIPステータス(1ヶ月分) | 通常より出金上限が高く、出金処理が最短1営業日に短縮されます。 |
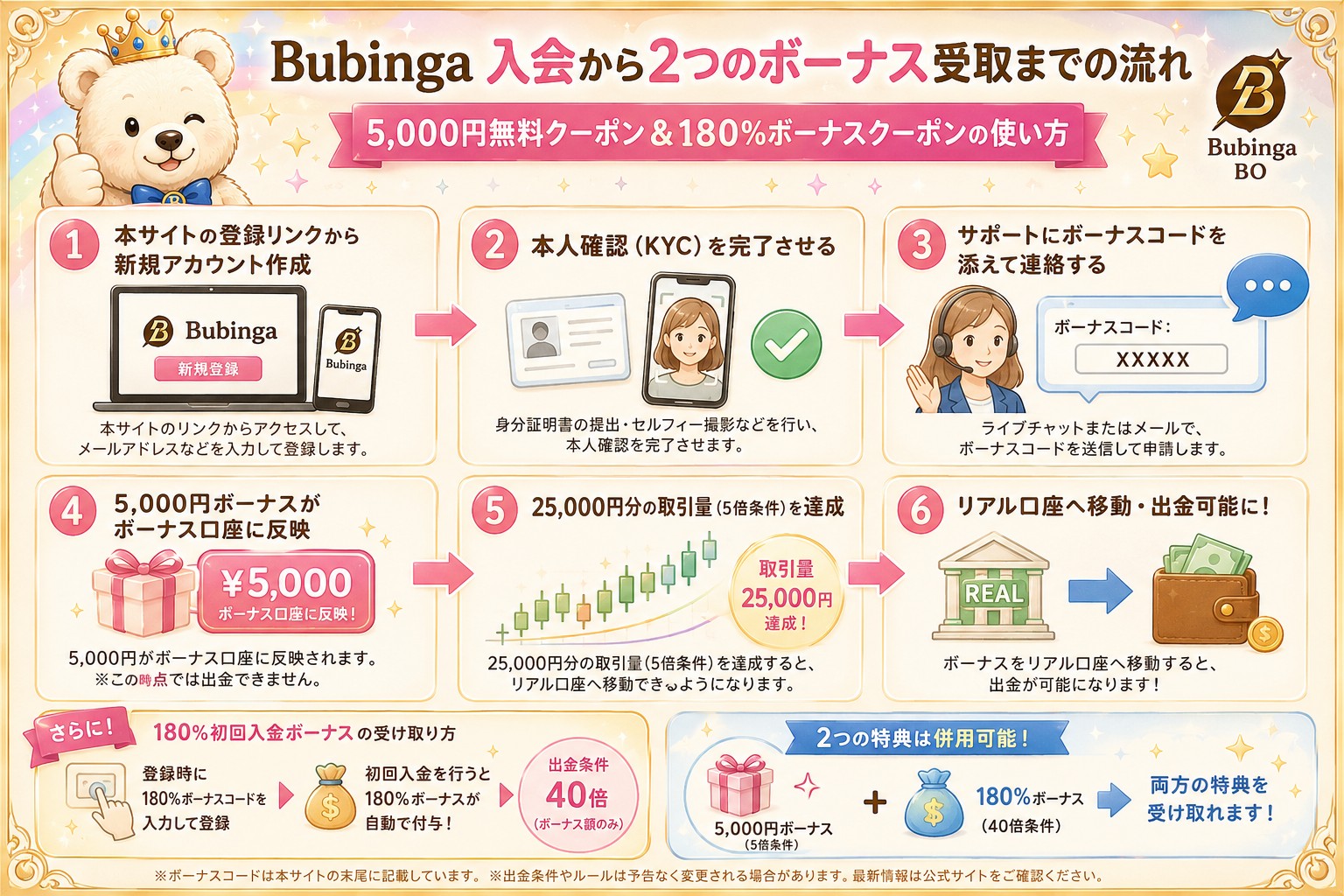
| 入金不要5,000円ボーナス | 入会時のコード入力、本人確認(KYC)完了後、サポートへ申請することで付与されます。 招待コード:SDA5000※出金条件5倍、上限10,000円 |
| 180% 初回入金ボーナス | 出金条件40倍。仕様を必ず事前に確認した上でご活用ください。 招待コード:SDA180※出金条件40倍、引き出し上限なし |
| サポートの強化 | アプリ内やメール([email protected])で、「そだし経由」とお伝えするだけで、顧客対応のレベルを上げていただくよう、幹部の方から情報共有済みです。 ※対応が著しく早くなったり、無理な融通が利くというわけではありませんが、孤独な夜のメンタルの担保にはなります。 |
🔍 あなたの「目的・温度感」に合わせて選ぶ検証ルート
どのような動機・背景でこの記事をここまで読み進めたかによって、確認すべきリスクと次に読むべきロードマップは異なります。おぬしの今のスタンスに最も近い項目を選択してください。
① 初心者・仕様をゼロから学びたい方へ
「バイナリーオプションの仕組みや、プラットフォームのルールを正しく把握したい」という場合は、まずシステムの裏側にある設計図を頭に入れることが最優先です。登録直後に実資金を投入する前に、必ず以下の2記事に目を通してください。
② 期待値・シミュレーションの整合性を確認したい方へ
本サイトで算出している「期待値」や「複利計算」「倍プッシュマーチンゲール」のデータは、すべてBubingaのクラシックモード(ペイアウト最大1.95倍)を前提にしています。計算上の数字がリアルな画面でどう動くか、まずは登録後すぐにリスクゼロで試せる「デモ口座」で、最低100回の試行ログを取ることを推奨します。
③ 取引環境と自身の「行動心理・悪癖」を記録したい方へ
「Bad Day(大敗する日)」の自動損切りシステムや、習慣化(Atomic Habits)の仕組みを機能させるには、実際の取引環境との擦り合わせが必要です。手法の優位性を探る前に、デモ環境を用いて「自分が連敗したときにどのような感情・破滅的行動パターンに陥るか」の冷徹な観察から始めてください。
④ 他社との構造的なリスク違いを比較・検証したい方へ
本サイトが数ある業者の中からBubingaを1つの検証枠として提示しているのは、「最も安全だから」ではありません。「少額入口・デモ口座の即時性・ボーナス仕様の透明性・VIPステータスによる出金速度・判定時間の検証可能性」の組み合わせが、最もルール化しやすいからです。他社との明確な構造比較は以下をご確認ください。
⑤ 予算を組んで即座に実戦(夜遊び・短期勝負)へ臨む方へ
「今夜、手元の3万円×2回を鉄火場でぶっ放す」という割り切った娯楽的運用であっても、プラットフォームの仕様による「予期せぬ出金の足留め」だけは絶対に避けねばなりません。資金を入金する前に、以下の3項目だけは確実にクリアしておいてください。
- 本人確認(KYC): 出金時に必須となります。後回しにすると処理が完全に止まります。
- 出金可能額の仕様: 残高=即時出金可能額ではありません。ボーナス枠の条件達成状況を確認してください。
- ステータス制限: スタート段階では1回あたりの最大取引額に上限があります(VIP特典による上限緩和を活用してください)。
- 3万円オールイン2連勝、精度高く遊ぶ夜|パチンコのラキトリより熱い夢の計算
- 出金拒否の構造|9割は知識で防げる
※こちらから入会すればVIP条件が1ヶ月付与されるため、入出金に手間取ることはありません。
